Introduction
Machine studying is a subfield of synthetic intelligence, which is outlined as the potential of a machine to simulate clever human conduct and to carry out advanced duties in a fashion that’s much like the best way people remedy issues.
To grasp machine studying, you have to know the algorithms that drive the alternatives of machine studying and it’s limitations.
Generally, machine studying algorithms are utilized in a variety of purposes, like fraud detection, laptop imaginative and prescient, autonomous autos, predictive analytics the place it isn’t computationally possible to develop standard algorithms that meet the necessities of actual time and predictive nature of labor.
There are three fundamental capabilities of machine studying algorithms –
Descriptive – Explaining with the assistance of information
Predictive – Predicting with the assistance of information
Prescriptive – Suggesting with the assistance of information
We perceive the capabilities of machine studying from the data above, however the artwork of constructing these capabilities work is in the best way wherein the algorithms are designed and used to execute these capabilities.
Forms of Machine Studying Algorithms
Within the subject of machine studying, there are a number of algorithms that assist us attain descriptive, predictive, and prescriptive consequence units primarily based on parameters outlined. Let’s study what these algorithms are within the subsequent part –
Studying Based mostly Machine Studying Algorithms
These algorithms, study primarily based on info offered and anticipated outcomes. There are various methods wherein these algorithms gasoline self studying.
Supervised Studying
Semi Supervised Studying
Unsupervised Studying
Reinforcement Studying
Supervised Studying
Machines are taught by instance in supervised studying. As an operator gives the machine studying algorithm with a recognized dataset with desired inputs and outputs, it should decide the right way to arrive on the inputs and outputs. Not like operators who know the proper solutions to issues, algorithms establish patterns in information, make predictions primarily based on observations, and study from them. Till the algorithm achieves a excessive degree of accuracy/efficiency, it makes predictions and is corrected by the operator.
Beneath the umbrella of supervised studying fall:
Classification: Noticed values are used to attract conclusions about new observations and decide which class they belong to in classification duties. When a program filters emails as ‘spam’ or ‘not spam’, it should analyze current observational information to find out which emails are spam or not spam.
Regression: In regression duties, the training machine should estimate and perceive the relationships between variables in a system by analyzing just one dependent variable, in addition to a variety of different variables which can be continually altering. Regression evaluation is especially helpful for forecasting and prediction.
Forecasting: Forecasting includes analyzing previous and current information to make predictions concerning the future.
Semi – Supervised Studying
A semi-supervised studying system is much like a supervised studying system, nevertheless it makes use of each labeled and unlabeled information along with supervised information. The time period labeled information refers to info that has a significant tag that permits the algorithm to grasp the info, whereas unlabeled information doesn’t have such a tag, which implies that machine studying algorithms may be taught to label information that has not been labeled.
Semi-supervised studying includes few elements.
(Classification or Regression Mannequin) – The above determine exhibits a classification mannequin. It’s first educated with labelled information.
A number of unlabeled information units are offered to the classifier after it has been educated on the labelled information. Upon classifying the unlabeled information, the mannequin is additional retrained utilizing the initially out there labelled information to extend the accuracy of the mannequin.
Instance of Semi-supervised algorithm contains the classification and regression issues.
Unsupervised Studying
It’s doable to establish patterns utilizing the machine studying algorithm, with out utilizing a solution key or an operator to offer directions. As an alternative, the machine analyzes out there information to be able to decide correlations and relationships. It’s left as much as the machine studying algorithm to interpret giant information units and tackle them accordingly in an unsupervised studying atmosphere. The algorithm tries to arrange the info in a fashion that describes the info’s construction. The info is likely to be grouped into clusters or organized in a extra organized method.
Because it assesses extra information, its skill to make choices on that information regularly improves and turns into extra refined.
The next fall underneath the unsupervised studying class:
Clustering: A clustering method includes grouping comparable information (primarily based on outlined standards). It’s helpful for segmenting information and discovering patterns in every group.
Dimension discount: In an effort to discover the precise info, dimension discount reduces the variety of variables thought of.
Affiliation rule mining: Discovering relationships between seemingly unbiased databases or different information repositories via affiliation guidelines.
Instance of Unsupervised algorithm is Ok-Means clustering, the Apriori algorithm.
Reinforcement Studying
In reinforcement studying, a set of actions, parameters and finish values are offered to a machine studying algorithm to be used in regimented studying processes. As quickly as the principles are outlined, the machine studying algorithm will discover a wide range of choices and potentialities, monitoring and evaluating every consequence to find out which one is the perfect. Machines study by trial and error utilizing reinforcement studying. Adapting its method to the scenario primarily based on earlier experiences helps it obtain the perfect end result.
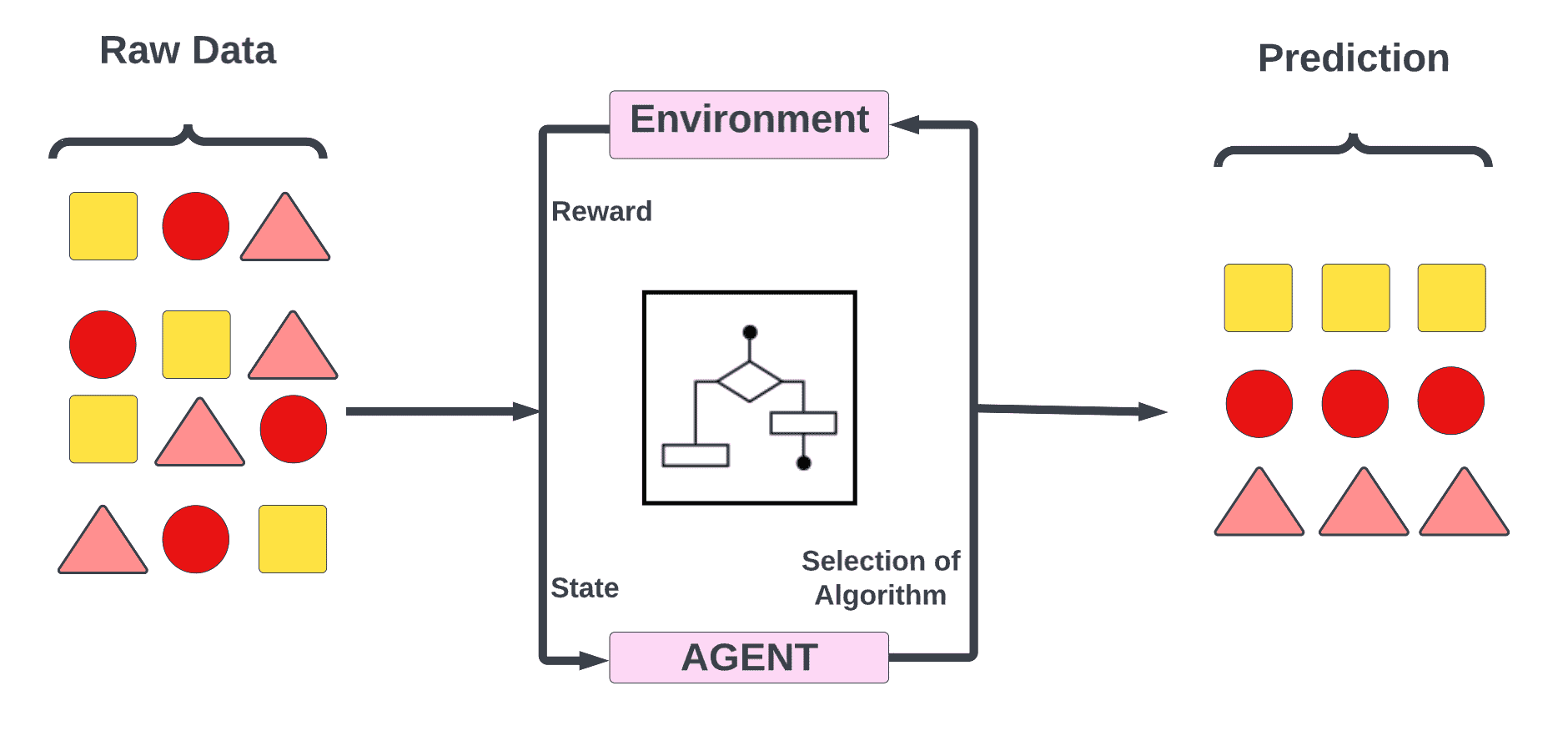 Reinforcement Studying – Machine Studying Algorithm
Reinforcement Studying – Machine Studying Algorithm
Machine Studying Algorithm Based mostly On Capabilities
Because of grouping by perform, we’re in a position to consolidate the totally different Machine Studying Algorithms primarily based on their methodology of operation. Regression algorithms may be divided into many differing types, however we’re going to group them collectively underneath one umbrella of the Regression Algorithms right here.
Regression Algorithms
Because the title implies, regression analyses are designed to estimate the connection between an unbiased variable (options) and a dependent variable (label). A linear regression is the tactic that’s most generally utilized in regression evaluation.
Among the mostly used Regression Algorithms are:
1. Linear Regression
2. Logistic Regression
3. Bizarre Least Squares Regression (OLS)
4. Stepwise Regression
5. Multivariate Adaptive Regression Splines (MARS)
6. Domestically Estimated Scatter Plot Smoothing (LOESS)
7. Polynomial Regression
Occasion Based mostly Algorithm
In Machine Studying, generalization is the flexibility of a mannequin to carry out effectively on new information situations that haven’t been seen earlier than. Generally, the principle objective of a Machine Studying mannequin is to make correct predictions. Actually, the true objective is to carry out effectively on new situations which have by no means been seen earlier than, slightly than simply performing effectively on educated information.
A Generalization method may be divided into two broad classes: Occasion primarily based studying and mannequin primarily based studying.
In addition to being generally known as instance-based studying, memory-based studying can also be a machine studying method wherein, as a substitute of evaluating new situations of information with those that had been noticed and realized throughout coaching, the algorithm compares these new situations of information with those that had been seen/realized throughout coaching.
Algorithms which can be generally utilized in instance-based studying embody the next:
1. k-Nearest Neighbor(kNN)
2. Resolution Tree
3. Help Vector Machine (SVM)
4. Self-Organizing Map (SOM)
5. Domestically Weighted Studying (LWL)
6. Studying Vector Quantization (LVQ)
Regularization Based mostly Algorithm
The regularization method is a sort of regression wherein the coefficient estimates are penalized in the direction of zero, serving to forestall the mannequin from buying a posh and versatile mannequin, thus avoiding overfitting in some conditions.
Some generally used regularization algorithms are:
1. Ridge Regression
2. Lasso (Least Absolute Shrinkage and Choice Operator) Regression
3. ElasticNet Regression
4. Least-Angle Regression (LARS)
Resolution Tree Algorithms
It is very important perceive that within the case of Resolution Tree, a mannequin of choice is constructed primarily based on the attribute values of the info. The selections maintain branching out and a prediction choice is made for the given document primarily based on the attribute values.
It’s generally used for classification and regression issues to coach choice timber as a result of they’re usually quick and correct.
Among the generally used choice tree algorithms are:
1. C4.5 and C5.0
2. M5
3. Classification and Regression Tree
4. Resolution Stump
5. Chi-squared Automated Interplay Detection (CHAID)
6. Conditional Resolution Tree
7. Iterative Dichotomiser 3 (ID3)
Clustering primarily based Algorithms
We are able to use a machine studying method generally known as clustering to categorise information factors into a selected group given a dataset with a wide range of information factors. To ensure that an information set to be grouped, we have to use a clustering algorithm. A clustering algorithm falls underneath the umbrella of unsupervised studying algorithms as it’s primarily based on the theoretical understanding that information factors that belong to the identical group have comparable properties.
Some generally used Clustering Algorithms are:
1. Ok-means clustering
2. Imply-shift clustering
3. Agglomerative Hierarchical clustering
4. Ok-medians
5. Density -Based mostly Spatial clustering of Purposes with Noisec(DBSCAN)
6. Expectation- Maximization (EM) clustering utilizing Gaussian Combination fashions (GMM)
Affiliation Rule Based mostly Algorithms
As a rule-based machine studying methodology, it’s helpful for locating relationships between totally different options in a big dataset through the use of a variety of guidelines.
It principally finds patterns in information which could embody:
1. Co-occurring options
2. Correlated options
Some generally used Affiliation rule studying algorithms are
1. Eclat algorithm
2. Apriori algorithm
{Bread} => [Milk] | [Jam]
{Soda} => [Chips]
As proven within the above determine, given the sale of things, each time a buyer buys bread, he additionally buys milk. Identical occurs with Soda, the place he buys chips together with it.
Bayesian Algorithms
In Classification and Regression, Bayesian algorithms observe the precept of Bayes’s theorem to find out the likelihood of an occasion primarily based on prior data of occasions and occurrences associated to the occasion.
Think about the truth that with age, there is a rise within the probabilities of creating some form of well being situation.
The Bayes theorem is ready to entry the well being situation of an individual extra precisely by conditioning it on the person’s age, primarily based on the prior data of well being situation in relation to age.
Among the generally used Bayesian Algorithms are:
1. Naïve Bayes
2. Gaussian Naïve Bayes
3. Bayesian Community
4. Bayesian Perception Community
5. Multinomial Naïve Bayes
6. Common One-Dependence Estimators (AODE)
Synthetic Neural Networks
Synthetic Neural Networks are branches of Synthetic Intelligence which are attempting to imitate the capabilities of the human mind. An Synthetic Neural Community is a set of related items or nodes that are known as synthetic neurons. Basically, this construction depicts the connectivity of neurons within the organic mind whether it is loosely modeled.
In a man-made neural community, crucial half consists of what’s generally known as neurons, that are the cells of the human mind which can be interconnected. The neurons of the neural community are interconnected identical to the cells within the human mind.
IMAGE
Parts of Synthetic Neural Networks
ANN has 3 classes of Neurons –
1. Enter Neuron.
2. Hidden Neuron.
3. Output neuron.
The opposite element of ANN is the activation perform which is used to generate the output from the hidden neuron to the output neuron. This output generated via the activation perform may be handed on to the following neuron which can later grow to be the enter to these neurons.
Some generally used Synthetic Neural Community Algorithms are:
1. Feed-Ahead Neural Community
2. Radial Foundation Operate Community (RBFN)
3. Kohonen self-organizing neural community
4. Perceptron
5. Multi-Layer Perceptron
6. Again-Propagation
7. Stochastic Gradient Descent
8. Modular Neural Networks (MNN)
9. Hopfield Community
Deep Studying Algorithms
A Deep Studying system is a department of Synthetic Neural Networks (ANNs) that are computationally extra highly effective and are in a position to remedy real-world issues like fixing real-time conditions that require giant and complicated neural networks to resolve effectively.
Among the generally used Deep Studying Algorithms are:
1. Convolutional Neural Networks (CNN)
2. Recurrent Neural Networks (RNN)
3. Lengthy Quick-Time period Reminiscence Community (LSTM)
4. Generative Adversarial Networks (GANs)
5. Deep Perception Networks (DBNs)
6. Autoencoders
7. Restricted Boltzmann Machines (RBMs)
Dimensionality Discount Algorithms
A dimension discount methodology includes reworking a high-dimensional information set right into a low-dimensional information set in a manner that retains the significant properties of the unique information even if the info has been remodeled from a high-dimensional area to a low-dimensional area.
In essence, Dimensionality Discount algorithms make the most of the construction of the info in an unsupervised method to be able to summarize or describe the info through the use of much less information or options than which can be current within the authentic information.
Among the generally used Dimensionality Discount Algorithms are:
1. Principal element evaluation (PCA)
2. Non-negative matrix factorization (NMF)
3. Kernel PCA
4. Linear Discriminant Evaluation (LDA)
5. Generalized Discriminant Evaluation (GDA)
6. Autoencoder
7. t-SNE (T-distributed Stochastic Neighbor Embedding)
8. UMAP (Uniform Manifold Approximation and Projection)
9. Principal element Regression (PCR)
10. Partial Least Squares Regression (PLSR)
11. Sammon Mapping
12. Multidimensional Scaling (MDS)
13. Projection Pursuit
14. Combination Discriminant Evaluation (MDA)
15. Quadratic Discriminant Evaluation (QDA)
16. Versatile Discriminant Evaluation (FDA)
Ensemble Algorithms
A number of fashions are utilized in ensemble strategies to enhance prediction efficiency which isn’t doable with both algorithm alone.
Among the generally used algorithms are:
1. Boosting
2. Bootstrapped Aggregation (Bagging)
3. AdaBoost
4. Weighted Common (Mixing)
5. Stacked Generalization (Stacking)
6. Gradient Boosting Machines (GBM)
7. Gradient Boosted Regression Timber (GBRT)
8. Random Forest
Supply: YouTube
What machine studying algorithms can you utilize?
There are a number of elements that must be considered when choosing the proper machine studying algorithm, together with, however not restricted to: the quantity of information, high quality and variety of the info, in addition to the solutions companies want to get from the info. Apart from accuracy, coaching time, parameters, information factors, and plenty of extra, choosing the proper algorithm additionally includes a mix of enterprise wants, specs, experiments, in addition to time out there.
What are the most typical and common machine studying algorithms?
Naïve Bayes Classifier Algorithm (Supervised Studying – Classification)
Based mostly on Bayes’ theorem, this classifier requires that every one values within the set of options are unbiased of one another, which can enable us to foretell a category/class with cheap confidence, primarily based on a given set of options.
Though it’s a easy classifier, it performs surprisingly effectively, and it’s typically used attributable to the truth that it outperforms extra advanced classification strategies, regardless of its simplicity.
Ok Means Clustering Algorithm (Unsupervised Studying – Clustering)
This algorithm works by categorizing unlabeled information, or information with out outlined classes and teams, which is a sort of unsupervised studying. Ok Means Clustering is one sort of unsupervised studying that can be utilized to categorize unlabeled information. Because of this algorithm, teams are discovered within the information, and the variety of teams is represented by a variable Ok. Utilizing the options offered, the algorithm then assigns information factors to one in every of Ok teams iteratively.
Help Vector Machine Algorithm (Supervised Studying – Classification)
There are a number of supervised studying fashions that can be utilized to research information. The Help Vector Machine algorithms analyze information for classifications and regressions. By offering a set of coaching examples, every set of examples is labeled as belonging to at least one or the opposite of the 2 classes, primarily filtering information into classes. Subsequent, the algorithm builds a mannequin, wherein new values are assigned to both a selected class or to a different class.
Linear Regression (Supervised Studying/Regression)
The best sort of regression is a linear regression. A linear regression permits us to grasp the connection between two steady variables by analyzing the info on a line.
Logistic Regression (Supervised studying – Classification)
The aim of a logistic regression mannequin is to estimate the likelihood that an occasion will happen primarily based on the earlier information that has been collected. The mannequin is used to cowl binary dependent variables, which implies there are solely two doable outcomes; 0 and 1.
Synthetic Neural Networks (Reinforcement Studying)
A synthetic neural community (ANN) includes a collection of ‘items’ organized in a collection of layers, every of which connects to layers on both facet. An ANN is an interconnected system of processing components that remedy particular issues in an asynchronous method. ANNs are modeled after organic programs, such because the mind.
They’re additionally extraordinarily helpful for modeling non-linear relationships in high-dimensional information or for difficult-to-understand relationships between enter variables. ANNs study via examples and expertise.
Resolution Timber (Supervised Studying – Classification/Regression)
Because the title suggests, a call tree is a sort of flowchart construction that makes use of a branching methodology for instance the doable outcomes of a specific choice. Every node of the tree represents a check performed on a selected variable, and every department represents the result of the check.
Random Forests (Supervised Studying – Classification/Regression)
Within the subject of ensemble studying, random forests, also called random choice forests, mix a number of algorithms to create higher outcomes for classification, regression and different duties. There are a number of weak classifiers within the algorithm, but when they’re mixed, they will produce wonderful outcomes. The algorithm begins by making a tree-like mannequin of selections (a call tree), after which including inputs to it on the high. Thereafter, the info is segmented into progressively smaller units, in accordance with particular variables, because it travels down the tree.
Nearest Neighbors (Supervised Studying)
Mainly, the algorithm identifies which group an information level is in primarily based on the info factors surrounding it. It primarily appears to be like on the information factors round a single level to find out what group it belongs to.
The fitting machine studying algorithms are essential to the success of your online business’ analytics and there are a lot of elements to contemplate when making the proper selection.
Conclusion
Supervised studying, as a dominant paradigm in machine studying, performs a important function within the improvement of clever programs able to making predictions or choices primarily based on historic information. By using labeled coaching information, supervised studying algorithms are adept at discerning patterns and relationships inside datasets, which they will later apply to unseen information. Its purposes are various and huge, starting from picture recognition and pure language processing to monetary forecasting and healthcare diagnostics. As know-how progresses, it’s anticipated that supervised studying will proceed to evolve, turning into extra environment friendly and correct. Nevertheless, it’s crucial to handle challenges similar to overfitting, information high quality, and moral issues to make sure that supervised studying continues to be a dependable and useful instrument within the broader spectrum of synthetic intelligence.