To grasp the dynamics of present open-source machine studying analysis, one platform is of central significance: Hugging Face. For accessing state-of-the-art fashions, Hugging Face is the place to be. On this put up, I analyse how fashions on this platform modified over the past years and what organisations are lively on Hugging Face.
Hugging Face, not OpenAI
Whereas a lot of current reporting on AI is concentrated on OpenAI, the corporate behind ChatGPT, one other firm that’s way more related to the on a regular basis lifetime of a Machine Studying (ML) developer, receives a lot fewer consideration: Hugging Face. Hugging Face is a platform that hosts ML fashions together with Massive Language Fashions (LLMs). Actually everybody can add and obtain their fashions on this platform and it is without doubt one of the major drivers for democratising analysis in ML. Subsequently, understanding what actors and fashions are on Hugging Face, tells us a lot about present open-source analysis in ML.
The corporate behind the emoji
Hugging Face is a younger firm that was based in 2017 in New York Metropolis. Its unique enterprise mannequin was offering a chatbot. Nonetheless, these days it’s principally referred to as a platform that hosts ML fashions. At first solely language fashions however within the current months imaginative and prescient, speech and different modalities have been added. Apart from free internet hosting, it additionally supplies some paid providers equivalent to a hub to deploy fashions. Hugging Face is presently rated at two billion {dollars} and just lately partnered with Amazon Internet Providers.
Fashions have gotten bigger
Contributions to Hugging Face are continually growing and repository sizes are rising over time (Fig 1). Because of this more and more giant fashions are uploaded, which mirrors current developments in AI analysis. Lots of the fashions are supplied by corporations, universities, or non-profits however most come from entities that present no info (“Different”). Handbook inspection exhibits that it consists of most frequently people who uploaded one or a number of fashions but in addition organisations that merely didn’t add their info.
Fig 1 Uploaded fashions over time and their repository sizes in Gigabyte (n = 151,296). Y-axis in log scale.
What varieties of organisations are lively on Hugging Face?
Who uploads the biggest fashions and whose fashions are most needed? The most important group when it comes to uploaded fashions is “Different” (Fig 2). The remaining teams, besides of “classroom”, are pretty shut to one another. Because of this universities, non-profits, and corporations contribute about equally on Hugging Face.
The current surge in ML analysis is usually pushed by Massive Tech and elite universities as a result of coaching giant fashions is extraordinarily resource-intensive when it comes to compute and cash. Accordingly, one would count on that the majority giant fashions come from corporations or universities and it’s also their fashions which can be downloaded essentially the most. However that is solely partly the case. Fashions by corporations and universities are most needed. Nonetheless, whereas fashions uploaded by corporations are additionally comparatively giant, fashions by universities will not be. The biggest fashions are uploaded by non-profits, nonetheless, that is principally due to a couple fashions by LAION and Massive Science, whereas every mannequin is greater than hundred gigabytes.
Fig 2 Uploaded fashions, repository measurement, and rely of downloads by (self-assigned) organisation kind. X-axis log scale.
Add and obtain will not be proportional
What are the person organisations that contribute essentially the most on Hugging Face? For universities, the College of Helsinki, who supplies translation fashions for numerous language mixtures, is main by far (Fig 3). Nonetheless, on the subject of downloads, the Japanese Nara Institute of Science and Expertise (NAIST) is main. That is principally resulting from MedNER, their named entity recognition mannequin for medical paperwork that can also be among the many high 10 of essentially the most downloaded fashions on Hugging Face. German universities are among the many organisations with the very best mannequin rely but in addition essentially the most downloads.
The non-profit repositories with essentially the most fashions shouldn’t be trusted an excessive amount of, since three of them are entertained by a single PhD scholar. Nonetheless, the organisations on this class with the very best obtain fee are well-known non-profit organisations like LAION and BigCode, that contribute loads to the open-source neighborhood.
Little shocking, Massive Tech corporations lead the trade class with respect to add counts. Nonetheless, it’s neither Google nor Fb who’ve the very best obtain fee however Runway with their Secure Diffusion mannequin.
The highest 10 of most downloaded fashions is led by Wave2Vec, a speech recognition mannequin. It’s shocking that regardless that Hugging Face was lengthy referred to as a platform for unimodal language fashions, most of the most downloaded fashions are bimodal for textual content and both imaginative and prescient or speech.
Fig 3 Organisations with the very best add/obtain rely.
Open-source LLMs are on the rise
Newest because the launch of ChatGPT, LLMs discovered their manner into public consideration. Nonetheless, according to a just lately leaked Memo from a Google-developer, open-source is turning into a critical competitor for LLMs. Hugging Face began a pacesetter board for open LLMs and a few of them attain efficiency near ChatGPT.
Mannequin measurement, measured in Parameters, elevated lately drastically (Fig 4). Whereas in 2021 solely few fashions reached 3 billion parameters, presently there are a lot of extra and bigger open fashions, reaching virtually 70 billion parameters.
The organisation kind that uploads essentially the most LLMs is “Different”. Nonetheless, that is principally pushed by a couple of actors, who uploaded typically much more than 15 fashions every. The group that uploads the second most LLMs are corporations and so they add LLMs with a mean of 10 billion parameters. Universities on the opposite aspect don’t solely add the fewest LLMs but in addition the smallest on common.
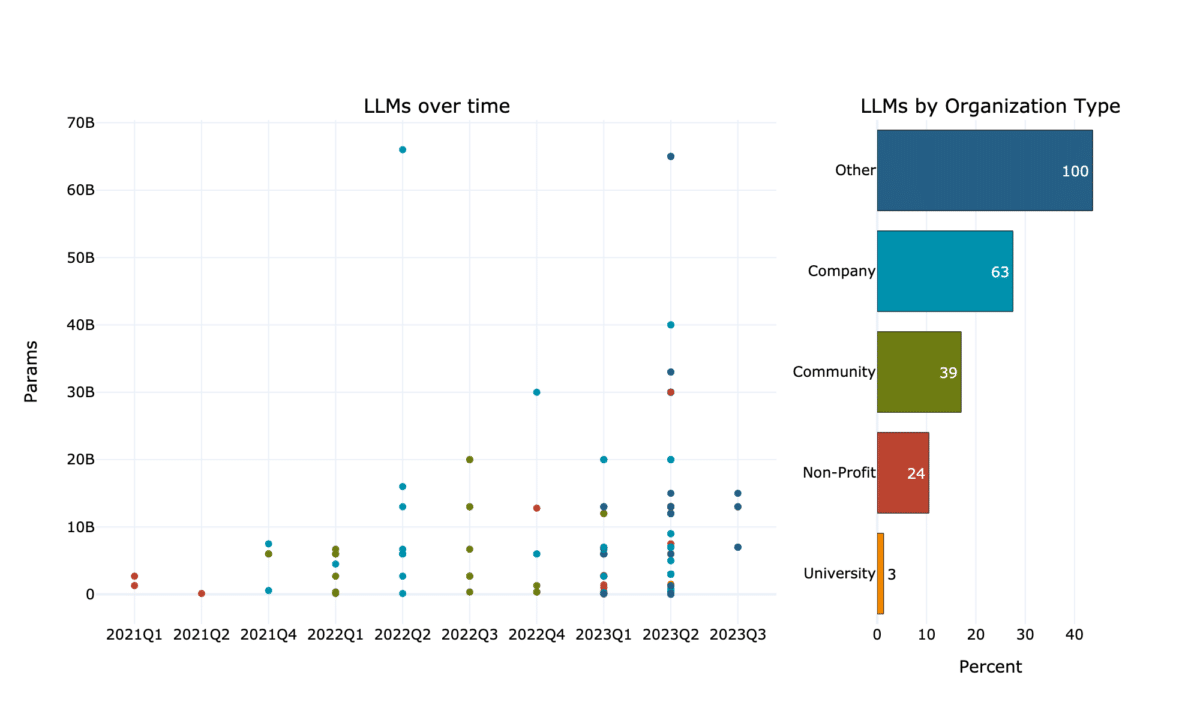
Fig 4 Parameter rely of Massive Language Fashions (LLMs) over time and by organisation kind (retrieved from Hugging Face’s LLM Leaderboard).
Massive fashions, giant emissions. Small fashions, small emissions
Excellent news first: coaching many of the fashions emitted much less CO2 than streaming in 4K high quality for one hour. The dangerous information is that solely a bit greater than 1% of the fashions at Hugging Face present this info. 1706 of those 1846 fashions that embrace emission info are from “Different”. Nonetheless, 99.5% of the emissions come from Non-Revenue fashions. Because of this coaching just a few fashions result in the largest share of emissions. This emphasises that the main a part of emissions comes from giant tasks and never from smaller ones. Nevertheless it additionally emphasises that it wants extra transparency and emissions should be documented extra constantly.
Fig 5 Coaching emissions (CO2/kg) for every mannequin and by organisation kind. Choice is restricted to repositories that embrace their emissions of their mannequin card (n = 1846). Pie chart shows the share of repositories that included this info by organisation kind. X-axis log scale.
Summing up
Hugging Face is the primary platform for distributing pre-trained ML fashions. With no platform like this, most smaller AI tasks wouldn’t have entry to state-of-the-art fashions. In a manner Hugging Face displays the present pattern in ML analysis: The sphere is dominated by a couple of actors who’ve the sources to coach more and more giant fashions. Nonetheless, regardless that coaching giant fashions is restricted to actors with adequate sources, Hugging Face permits tasks with much less sources to make use of those fashions. Furthermore, regardless that giant corporations draw most consideration, there’s a vivid base of small- and mid-sized tasks producing fixed output and solely small emissions.
Technique & limitations
All information was scraped starting of July 2023. As progress occurs quick in ML analysis, the numbers won’t be totally correct already. For info on the fashions, Hugging Face’s personal API was used. Info on the organisations was retrieved with a customized scraper. Customers on Hugging Face have the choice to add info sheets, playing cards as they name them. These playing cards present info on organisations, datasets, or fashions and they’re the primary supply that informs this text. All info on organisations is self-assigned and there are a variety of empty repositories and fake-organisations. For instance, whereas Hugging Face presents greater than 260,000 fashions in accordance with their search engine, solely about 150,000 of those repositories are bigger than ten megabytes. Since ML fashions require a lot reminiscence, it’s unlikely that these repositories really comprise fashions. I imagine that the overall pattern is right however some particulars may be inaccurate. The detailed info on particular person organisations have been retrieved manually and to the perfect of my information.